The Thundering Herd Problem
How a single cache expiry can take down your entire back end — and the five techniques that stop it.

What Is It?
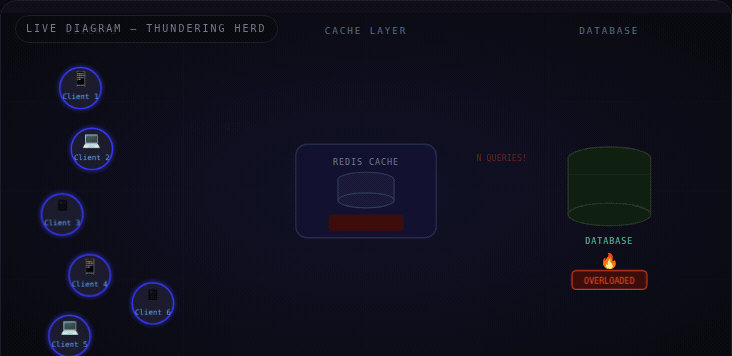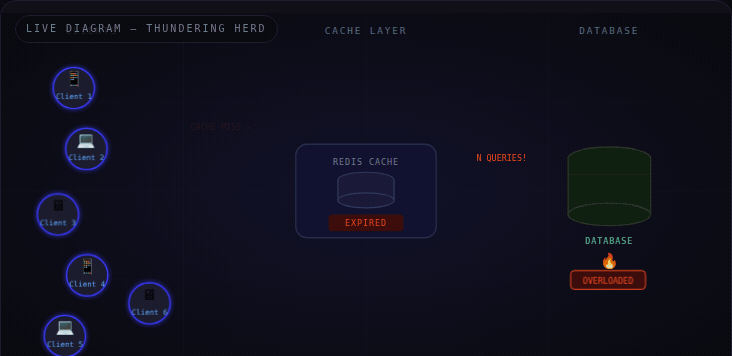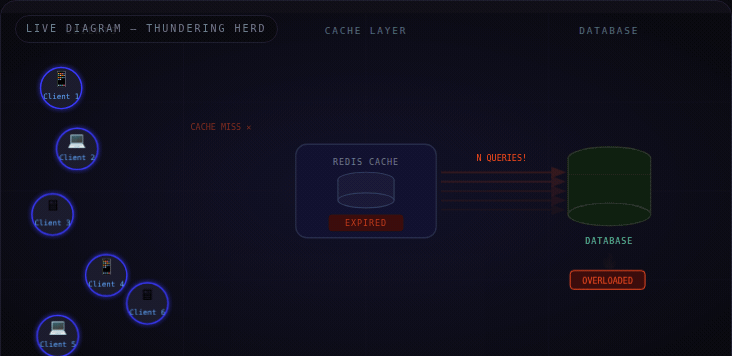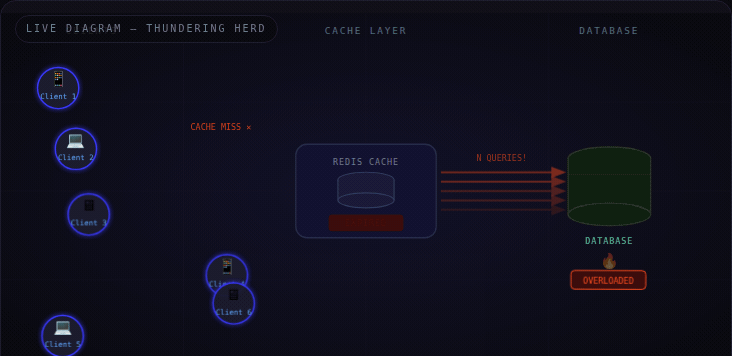
The Thundering Herd Problem happens when a large number of servers simultaneously request the same resource that just became unavailable — most commonly, an expired cache key.
Think of it like a store opening at 9 AM. 500 people are waiting outside. The second the door unlocks — everyone rushes in at once. The shelves collapse. The staff can't cope. Not because there were too many people overall — but because they all arrived at the exact same moment.
Replace the store with your database. Replace the crowd with your app servers. Replace 9 AM with the moment your Redis TTL hits zero.
⚡ It's not a volume problem — it's a synchronization problem. A thousand requests over an hour is fine. A thousand requests in the same millisecond on a cold cache is an outage.

How It Happens
Here's the failure sequence when a cached key expires at peak traffic:
T=0 · Cache key dropsT+1ms ·
All servers: cache MISST+2ms ·
All servers fire DB queriesT+50ms ·
DB connection pool fullT+500ms ·
Timeouts → retries (worse)T+10s · 503 errors · site down
The naive code pattern that causes this looks completely innocent:
//Looks fine. Will destroy your DB under load.
async function getData() { let data = await redis.get('homepage'); if (!data) {
// All 50 servers hit this at the same millisecond
data = await db.query('SELECT * FROM articles LIMIT 20'); await redis.set('homepage', data, 'EX', 60); } return data; }

Real-World Examples
Hotstar / IPL — 35M concurrent viewers. A scorecard cache expiring mid-match means tens of thousands of simultaneous DB queries. Hotstar built custom thundering-herd-resistant layers for exactly this.
Netflix — A show drops at midnight. Millions check "What's New" simultaneously. If recommendation caches were set to expire at midnight, the herd triggers at peak traffic. Netflix uses probabilistic refresh to prevent it.
Stack Overflow — Documented using mutex-based cache refresh so only one thread rebuilds any given key, regardless of how many readers are waiting.
How to Fix It
Five battle-tested techniques — pick based on your use case:
🔒 Cache Locking (Mutex) — Only one server refreshes the cache. Others wait 50ms or return stale data. One DB query instead of fifty.
const lock = await redis.set('key:lock', '1', 'NX', 'EX', 5); if (lock) { // Only this server hits the DB
const data = await db.query(...); await redis.set('key', data, 'EX', 60); await redis.del('key:lock'); } else { await sleep(50); // wait and retry — cache will be warm }
🎲 TTL Jitter (Simplest fix) — Add random variance to every TTL. Keys expire at different times instead of all at once. One line of code.
// Instead of a fixed 60s for everyone:
const ttl = 60 + Math.floor(Math.random() * 20 - 10); // 50–70s
await redis.set('key', data, 'EX', ttl);
🔀 Request Coalescing — 500 requests for the same key collapse into 1 upstream DB query. All 500 wait for that single result.
⏱ Exponential Backoff — Retry after 1s → 2s → 4s → 8s. Prevents retry storms from amplifying the failure.
♻ Background Refresh — Refresh cache at T+55s before the 60s TTL expires. Cache is always warm. Users never cause a miss.

📌 Key Takeaways
Cache expiry + many servers = synchronized DB flood
It's a synchronization problem, not a traffic volume problem
Adding more servers makes itworse
TTL jitter is the simplest fix — always add it
Cache locking (mutex) is the most complete fix
Background refresh gives the best user experience